

Vector vs Benthos

In this article, we will contrast two stream-processing platforms: Vector - by Datadog versus Benthos - by Ashely.
TL;DR
Stream processing
Will start with answer to the question What is Stream processing at all?
Event-Driven-Development
To address that question, we need to take a step back and examine traditional development versus event-driven development.
In the traditional approach, also known as request-response development, the flow is linear and occurs synchronously. For instance, consider a transaction on an e-commerce website. The steps would be as follows:
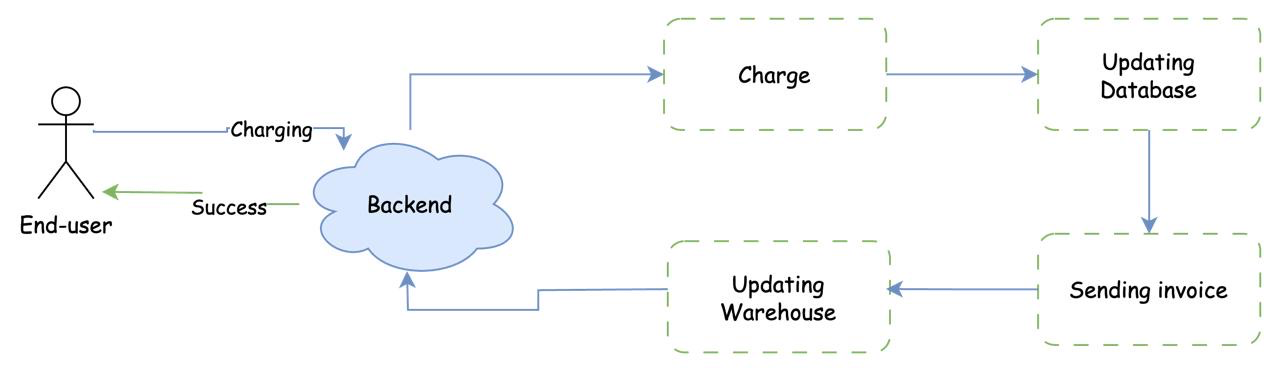
The user enters credit card details and submits the form.
The details are sent to the backend.
The backend charges the card via the payment gateway while the user waits.
After successfully charging the card, the backend updates the database.
The backend sends an invoice to the user.
The backend sends an email to the warehouse to initiate order fulfillment.
Finally, the backend sends a response indicating success.
In many cases, the traditional approach suffices; however, there are instances where it can be considerably error-prone.
Firstly, the flow can diverge or alter at any point if one of the steps fails. For instance, suppose the payment charge and invoice sending succeed, but the warehouse notification fails. How do you track and recover from such failures?
Additionally, the end-user must wait throughout the entire process, whether it takes 2 seconds or 60. While this may be tolerable for many scenarios, it can pose a significant issue in others.
For instance, consider IoT applications where each device must report to a central base every N seconds. If the base's response time exceeds a few milliseconds, it can lead to a bottleneck of data, blocking other IoT device requests and compromising overall throughput.
To summarize, the issues with the request-response approach are:
Lack of fault tolerance and inability to recover from failures.
Blocked processing until the entire process is completed.
To address these challenges and handle a large volume of requests, you may consider adopting Event-Driven Development (EDD).
In EDD, the flow operates asynchronously. The key components of EDD are:
Event store: Such as Kafka or RabitMQ, where all events are stored
Producer: Responsible for sending events to be stored in the event store, organized by topics
Consumer: Registers in the event store to receive all events from specific topic(s).
For instance, a producer might generate an event in the "function-execution" topic, containing execution data. Subsequently, consumers subscribed to the "function-execution" topic will receive the event data and process it accordingly.
This approach redefines the flow of the e-commerce example within an EDD framework.
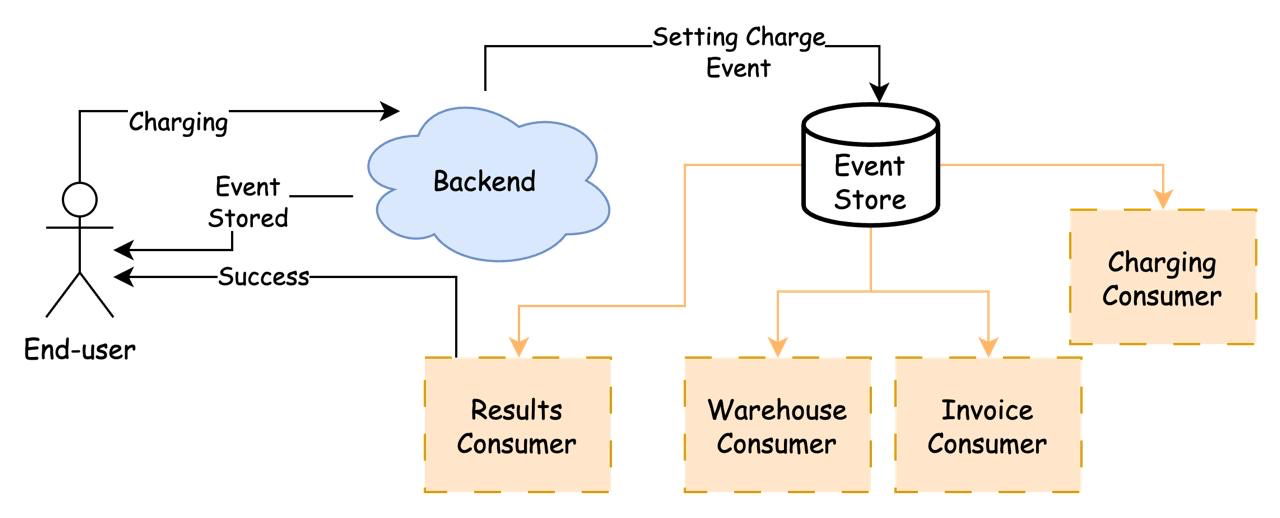
The user enters credit card details and submits the form.
The details are sent to the backend.
The backend produce a charge event and stores it in the event store.
The backend sends a success message from the
event store(the user receives a response).The charging consumer retrieves the event from the event store, charges the card, and sends the event back to the event store.
Then, the invoice consumer processes the event, sends it back, and continues the flow.
Then, the warehouse consumer processes the event and sends it back.
Then, the invoice consumer sends the event back to the end-user..
In this example, Event-Driven Development (EDD) may appear more complex than the traditional approach. However, by introducing one more step, we gain several significant benefits:
Fast: Producing events takes mere milliseconds, ensuring that your throughput remains unblocked.
Asynchronously: Event processing within consumers occurs in the background, reducing the processing load on the main endpoint.
Fault tolerant: Most data stores retain all events on disk, making the system resilient to failures.
Guaranteed delivery: Each event must be committed, ensuring that events are resent until processing is completed successfully.
Extendible: Adding additional steps is straightforward; just add a new consumer.
Scalable and distributed: Event stores like Kafka are distributed by default, making them easy to scale across multiple servers and consumers.
Stream processing
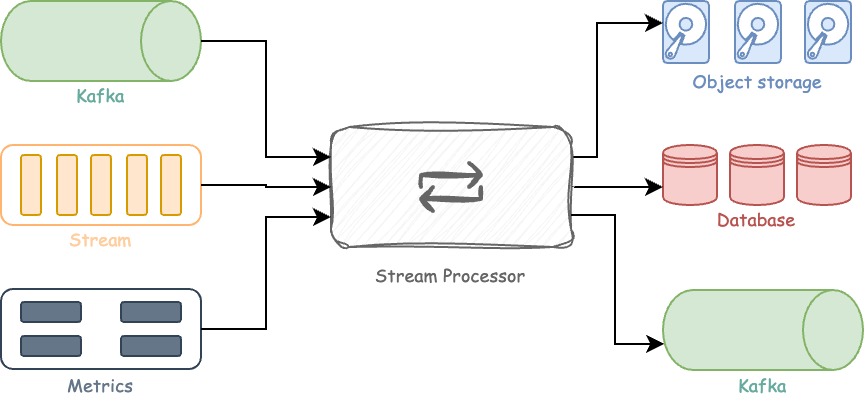
When it comes to handling messages from an event store like Kafka, stream processing plays a crucial role. Stream processing can be achieved using various SDKs or by utilizing a stream processor.
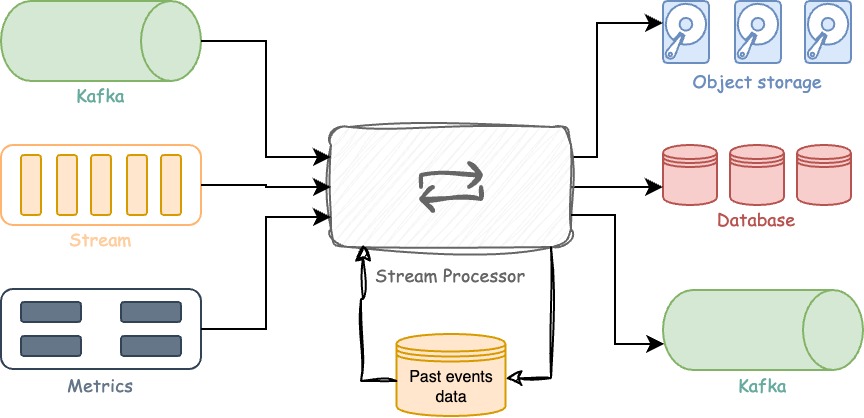
A stream processor is a pre-built solution that typically consists of three main components:
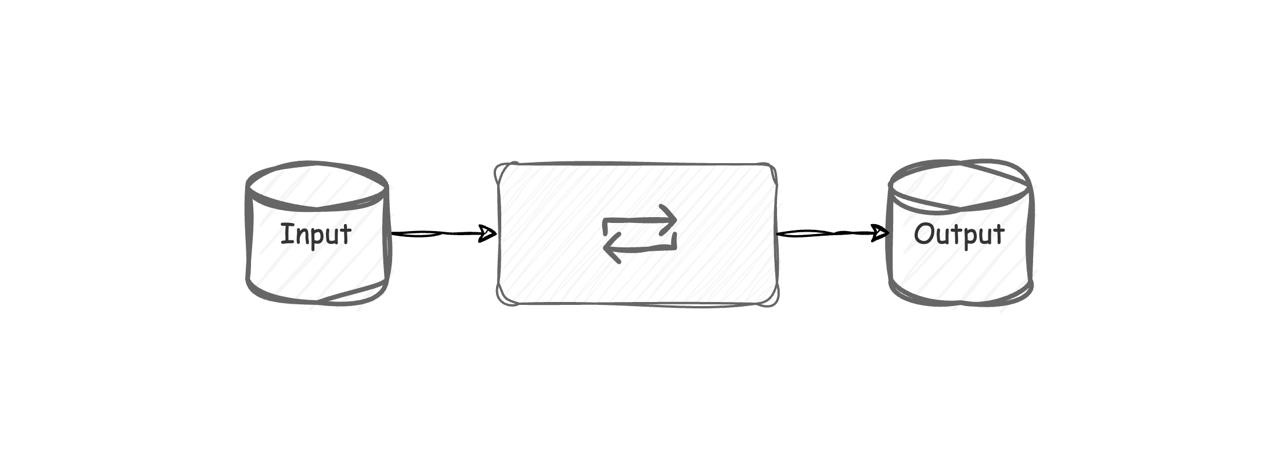
Inputs or Sources - These are the origins from which the streams obtain their data. Examples include Kafka, AWS SQS, URL endpoints, and system metrics.
Enrichment or Processors - Messages received from the inputs are processed here. Examples of processing tasks include filtering, removing sensitive data, type conversion, validation, and more.
Outputs or Sinks - This is where the processed data is sent. It could be a database, an S3 bucket, or even another Kafka instance.
Why choose a stream processor over writing code?
While it's possible to achieve similar results by writing custom code, stream processors offer several advantages. One key advantage is that stream processors come with everything pre-configured, and they often cover most common use cases. This means you can get up and running quickly without needing to set up and fine-tune every aspect of your data processing pipeline.
Stateless vs Stateful streaming
In stream processing, there are two main approaches: stateless and stateful processing, each defining how incoming data is handled.
Stateless
In stateless processing, events are processed as they arrive without considering previous event processing. This means each event in the stream undergoes the same processing steps and follows the same pipeline.
Common examples of stateless streams include:
Metrics gathering
Database replication
Log aggregation
General tasks that don't rely on knowledge of other events.
ile it's possible to process data based on past events in a stateless approach, it typically requires manual modifications and isn't inherent to the process.
Stateful
In the stateful approach, the processing pipeline can dynamically adjust based on previous data. Examples of stateful processing include:
Infrastructure abuse monitoring: Requires past event data for effective monitoring, as gathering this information without historical context can be challenging.
Fraud detection
Search result optimization
Any event data that benefits from insights gained from previous events.
Stateful processing is well-suited for scenarios where historical context or insights are crucial for accurate and meaningful data processing.
Both Vector and Benthos are stateless stream processors. While Vector does offer some stateful options, such as RAM-State, these are temporary and will be lost if Vector is terminated.
Why about others?
Other popular solutions for stream-processing are:
| Package | Goal | Languages |
| Spark | Batch data processing | Java, Scala, Python |
| Smaza | Event processing. | Java |
| Storm | [Stateful] event streaming | Java, Scala, Python, Clojure, Ruby |
| Flink | Stateful event streaming | Java, Scala, Python |
| Kafka Streaming | Kafka-source-only event streaming. | Java |
Maybe some day we'll do an article to explain why so many packages for the same thing.
Each of those solution is a bit different then the others, but the main reasons to use Benthos or Vector is because they are language agnostic, both of them uses yaml with toml in Vector.
Conceptual differences
Idea
The main difference between Vector and Benthos lies in their primary objectives:
Vector aims to serve as a data/log/metrics aggregator, employing a stream-processing approach.
Benthos, on the other hand, focuses on providing a stream-processing solution specifically for events.
Despite these differing goals, both solutions are capable of handling many stream processing tasks, which is why a comparison between them is relevant and useful.
Lang
Vector is written in Rust, and Benthos is written in Go. Both are a very efficient general-purpose languages. And, even that some might claim that Rust is faster we will omit that advantage from Vector.
Usage differences
Both Vector and Benthos provide a diverse range of inputs, processors, and outputs. To compare their differences effectively, we'll focus on components that are unique to each solution.
Inputs - Sources
The differences in the inputs is that Vector is more toward logs, and as of such it includes log inputs like:
Docker logs
k8s logs
Datadog agent and more
Benthos goes towards the events goal and haves inputs as:
SQL Select (for
mysql,postgres,clickhouse,mssql,sqlite,oracle,snowflake,trino,andgocosmos)Discord (new message)
and, Twitter search.
Both of the solutions shared support for the most popular services as:
AMQP
AWS Kinesis Firehose
AWS S3
AWS SQS
HTTP Client - Check for update
HTTP Server - Listen for update.
File
Kafka
Redis
Socket
GCP PubSub
Exec (getting output from a local binary)
stdin
Vector Remap Language (VRL) vs Bloblang
Voth VRL in Vector and Bloblang in Benthos serve as type-agnostic languages for remapping and processing various data formats like JSON, XML, or others. They allow you to transform and manipulate data without being tied to a specific data type, which is particularly useful in handling diverse event data.
Given this event data
{
"events": [
"1:file_uploaded",
"2:alram_set_up",
"3:file_found",
"4:sytsem_shutdown"
]
}
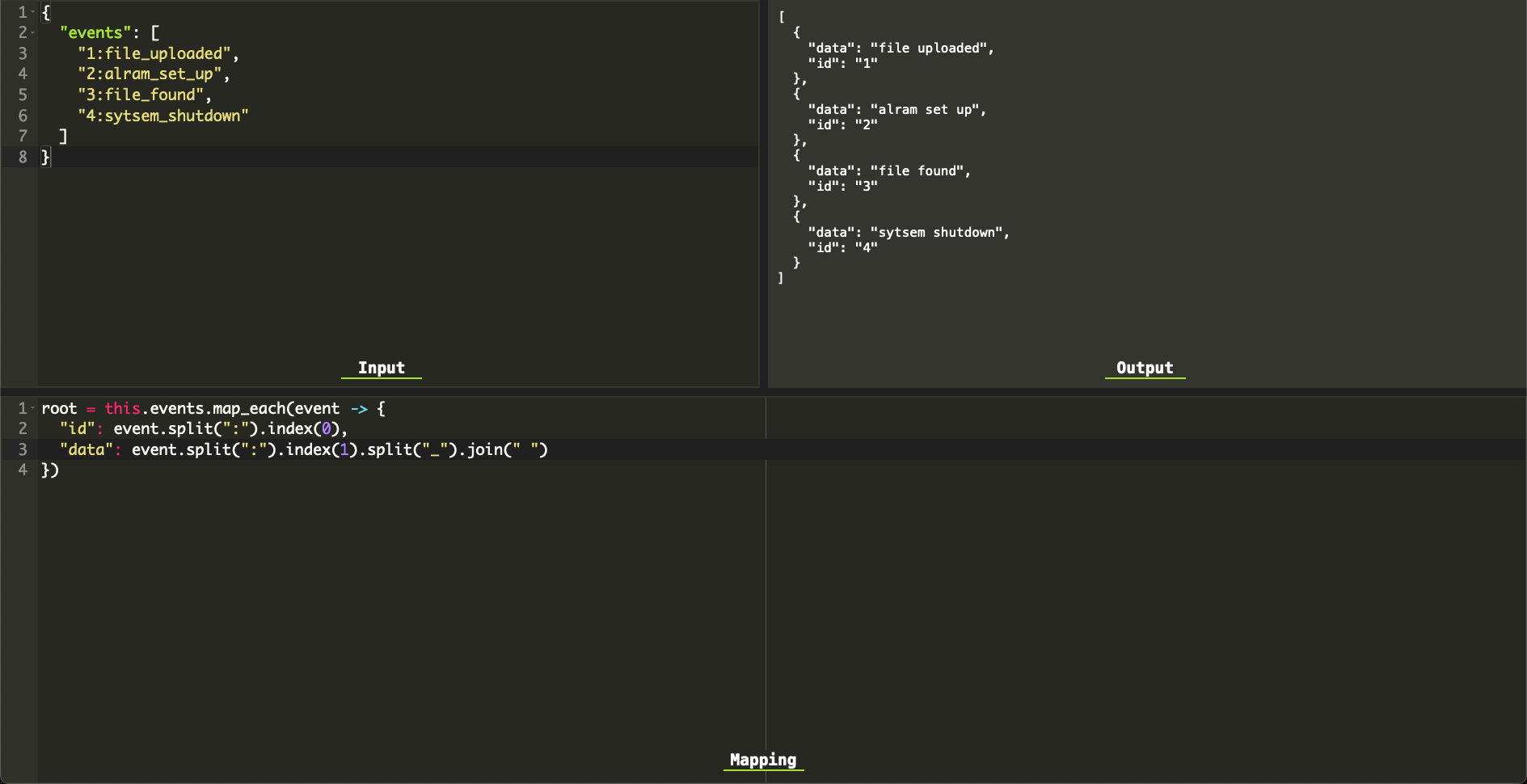
As we can see the events data contains the : to separate between the event ID and the event data, and the event data space uses _. we'll use both languages to enrich that event data. We'll start with Bloblang
root = this.events.map_each(event -> {
"id": event.split(":").index(0),
"data": event.split(":").index(1).split("_").join(" ")
})
This code will map each of the events to an id and data object and will put the results inside the root element, so will have something like such:
[
{ "data": "file uploaded", "id": "1" },
{ "data": "alram set up", "id": "2" },
{ "data": "file found", "id": "3" },
{ "data": "sytsem shutdown", "id": "4" }
]
TIP: Run benthos blobl server to get fully working REPL for practicing your Bloblang
In Vector VRL is a bit different. (Use this website to practice on VRL)
e = []
for_each(array!(.events)) -> |_index, value| {
a, err = split(value,":")
text, err2 = split(a[1], "_")
joined, err3 = join(text, " ")
e= append(e,[{"id":a[0], "event":joined}])
}
. = e
The main difference is that VRL variables don't have methods so instead of text.split we must write split(text), imo it gives Bloblang a small advantage.
Output - Sinks differences
In the outputs section we once more see the goal diffrences, while both of the solutions supports common outputs as:
AWS Kinesis Data Firehose logs
AWS Kinesis Streams logs
AWS S3
AWS SNS
AWS SQS
Azure Blob Storage Console
GCP Cloud Storage
GCP PubSub
HTTP
Kafka
Redis
Vector will go more toward the logs way as loki and Benthos towards the general data organizer as sftp.
Scalability
Scalability is a key advantage of stateless tools like Benthos and Vector. They can scale easily by adding more instances of the tool. Running them in Docker containers is a recommended approach for ensuring smooth operation without interference.
For large deployments, Benthos offers features like a Kubernetes (k8s) operator and a Helm chart for managing deployments efficiently. Similarly, Vector also provides a Helm chart for streamlined deployment.
One unique advantage of Vector is its agent-to-aggregator concept. This allows you to distribute workload among Vector instances and centralize stream processing, creating a single source of truth. For instance, each server can have a Vector agent gathering Docker logs, which are then sent to another Vector acting as an aggregator, responsible for filtering and enriching the data.
Extending
Want to create your own inputs, processors or outputs? for now it's possible only with Benthos. check this repo.
Example
Both of the tools can be run in the same way.
$# benthos -c config.yml
$# vector --config config.yml
The config.yml will contain all description of the pipeline process.
Benthos
input:
generate:
mapping: |
root.id = uuid_v4()
root.name = fake("name")
root.email = fake("email")
interval: 1s
pipeline:
processors:
- mapping: |
root.id = this.id
root.length = this.id.length()
root.details = this.name + " - "+this.email
- mapping: root = this.format_xml()
output:
broker:
outputs:
- stdout: { }
- file:
path: ./a.txt
codec: lines
In this example we are running the generate input every 1 second, and generating an object with fake ID, fake name and fake email.
Then, we use the mapping processor. First adjusting the field, and, then formatting the output as XML.
Then, the data will be output to the stdout and will be appended to a local file named a.txt.
Vector
sources:
generate_syslog:
type: "demo_logs"
format: "json"
count: 100
transforms:
remap_syslog:
inputs:
- "generate_syslog"
type: "remap"
source: |
j = parse_json!(.message)
date = parse_timestamp(j.datetime,format: "%v %R %:z") ?? now()
dt = to_unix_timestamp(date) / 3600
. = {"method":j.method, "host":j.host, "referer":j.referer,"date":to_int(floor(dt))}
remove_date:
inputs:
- remap_syslog
type: "remap"
source: |
del(.date)
.referer, err = replace(.referer, "https://", "")
indexOfSlash = find(.referer, "/")
.referer, err = slice(.referer, 0,indexOfSlash)
sinks:
emit_syslog:
inputs:
- "remove_date"
type: "console"
encoding:
codec: "json"
In this example will generate 100 lines of JSON demo_logs, then, in the transformers sections we first remapping the data, then removing the https and suffix part of each domain.
At the end the data being output to the console using json codec.
Conclusion
A great solution could be mixing both tools. For example, gathering metrics using Vector and send it to Benthos and so on.
If you're main goal is to gather logs and insights from your infrastructure Vector would be the way to go. In any other case using Benthos or both of the tools together will be the best.



